CAP Theorem
Core Concept
Understanding the fundamental trade-offs in distributed systems design and implementation
CAP Theorem
The CAP theorem is a fundamental principle in distributed systems that addresses the challenge of designing systems that handle network failures while maintaining data consistency and availability. Proposed by Eric Brewer in 2000 and formally proven by Seth Gilbert and Nancy Lynch in 2002, it states that any distributed data store can simultaneously guarantee at most two of the following three properties:
- Consistency (C): Every read receives the most recent write.
- Availability (A): Every request receives a response, without guarantee that it contains the most recent write.
- Partition Tolerance (P): The system continues to operate despite network partitions or communication failures between nodes.
In practice, network failures are inevitable in distributed systems, so partition tolerance is a given. This leaves a trade-off between consistency and availability. Systems typically fall into one of two categories:
- CP Systems (Consistency + Partition Tolerance): Prioritize data consistency over availability. Example: Banking transactions.
- AP Systems (Availability + Partition Tolerance): Prioritize system availability, allowing eventual consistency. Example: Comments on YouTube or Instagram.
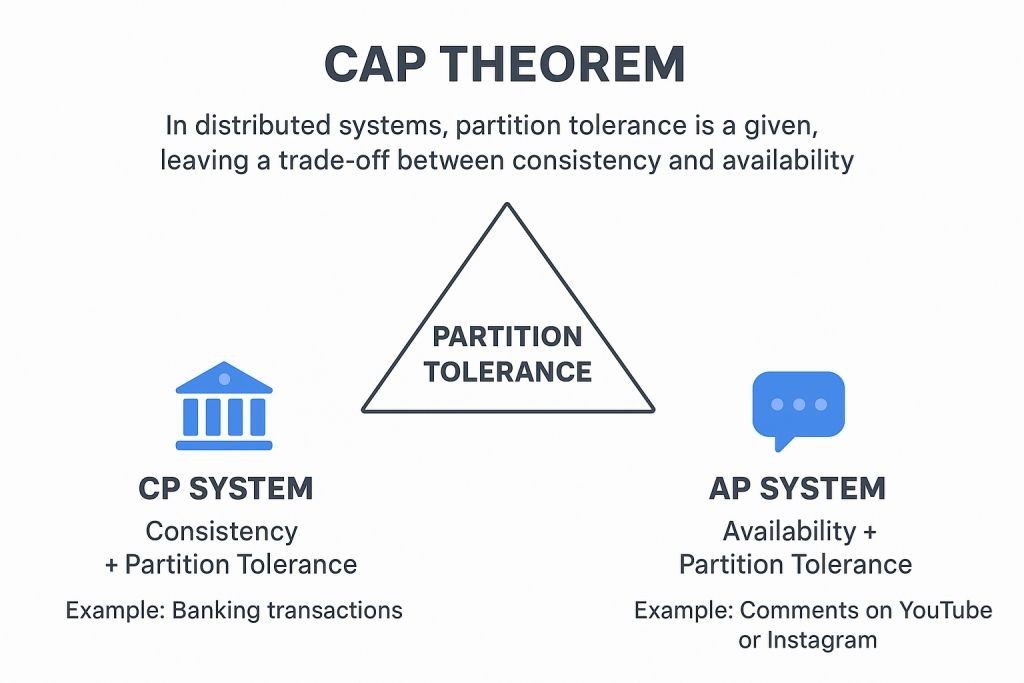
The CAP theorem triangle showing the fundamental trade-offs in distributed systems design. In practice, partition tolerance is a given, leaving systems to choose between consistency and availability.
The main technical challenges this addresses include:
- Network partition handling: How systems behave when nodes cannot communicate
- Data consistency across replicas: Ensuring all nodes have the same view of data
- Service availability during failures: Maintaining system responsiveness under adverse conditions
Core Principles: The Three Properties
Consistency (C)
Consistency ensures that every read operation receives the most recent write or an error, like having a single source of truth that everyone agrees on. All nodes in the system have an identical view of the data at any given time, similar to everyone looking at the same clock.
Technical Implementation:
Consistency is achieved through synchronous replication across all nodes, ensuring changes are propagated before acknowledging them. Distributed locking mechanisms prevent concurrent modifications that could lead to inconsistencies. Consensus algorithms like Raft and Paxos coordinate decisions across nodes. Atomic commit protocols such as 2PC and 3PC ensure that operations either complete fully or not at all.
Real-World Examples:
Traditional RDBMS systems like PostgreSQL and MySQL with synchronous replication provide strong consistency guarantees. Distributed databases like Google Spanner and CockroachDB achieve global consistency through sophisticated coordination. Banking systems prevent double-spending by ensuring account balances are always accurate. E-commerce inventory systems prevent overselling by maintaining consistent stock counts.
Consistency Levels:
Different applications require different levels of consistency. Strong consistency provides immediate consistency across all nodes, like having everyone see the same data instantly. Sequential consistency ensures operations appear in some sequential order, similar to having a consistent timeline of events. Linearizability provides the strongest consistency model for concurrent systems, guaranteeing that operations appear to occur atomically.
Availability (A)
Availability ensures that the system remains operational and responsive to requests, like having a store that's always open for customers. Every request receives a response, though it may not reflect the most recent write, similar to getting an answer even if it's slightly outdated.
Technical Implementation:
Availability is maintained through redundant system components that can take over if others fail. Load balancing and failover mechanisms distribute traffic and automatically switch to backup systems. Asynchronous replication allows systems to continue operating while updates propagate in the background. Circuit breaker patterns prevent cascading failures by isolating problematic components.
Real-World Examples:
CDN networks like CloudFlare and AWS CloudFront serve cached content to ensure fast, reliable access. Social media platforms like Facebook and Twitter maintain feed availability even during partial outages. E-commerce sites like Amazon keep their product catalogs accessible even when some systems are down. DNS systems use hierarchical resolution with caching to provide reliable name resolution.
Availability Patterns:
Different availability patterns suit different use cases. Active-Passive systems maintain hot standby systems that can quickly take over if the primary fails. Active-Active systems have multiple active nodes serving requests simultaneously. Geographic distribution spreads systems across multiple regions to handle regional outages.
Partition Tolerance (P)
Partition tolerance ensures that the system continues to operate despite network failures, arbitrary message loss, or communication breakdown between nodes. It's like having a resilient organization that can continue functioning even when some departments lose communication with each other.
Technical Implementation:
Partition tolerance is achieved through network failure detection algorithms that identify when nodes become unreachable. Split-brain prevention mechanisms ensure that isolated partitions don't make conflicting decisions. Quorum-based decision making requires majority agreement before proceeding with operations. Gossip protocols enable state synchronization even when direct communication is disrupted.
Real-World Examples:
Multi-datacenter systems spanning AWS regions demonstrate partition tolerance by continuing to operate even when regions become isolated. Microservices architectures with service mesh provide network resilience by automatically routing around failed components. Mobile applications with offline-first design continue functioning even with intermittent connectivity. IoT systems use edge computing to handle operations locally when network connections are unreliable.
Partition Scenarios:
Different types of partitions can affect distributed systems. Geographic partitions occur due to undersea cable cuts or regional outages that isolate entire regions. Rack-level partitions happen when switches fail or power outages affect specific server racks. Process partitions occur due to software bugs or resource exhaustion that prevent communication between processes.
Practical Implementation Patterns
CAP Trade-off Visualization
System Architecture Diagram
CP Systems (Consistency + Partition Tolerance)
CP systems prioritize data accuracy over service availability, like a bank that closes its doors during a computer system update to ensure all transactions are processed correctly. During network partitions, these systems sacrifice availability to maintain consistency, becoming unavailable rather than serving potentially stale or incorrect data.
Implementation Patterns:
CP systems use consensus-based approaches like Raft and Paxos for leader election, ensuring that only one node can make decisions at a time. Quorum systems require majority voting for operations, preventing split-brain scenarios. Synchronous replication waits for acknowledgment from all replicas before considering an operation complete.
Real-World Examples:
- MongoDB (default): Primary-secondary with read concern "majority"
- Apache HBase: Strong consistency through single master
- etcd/Consul: Service discovery with strong consistency
- Banking Core Systems: Account balance updates
Production Considerations:
// MongoDB with strong consistency
const result = await collection.findOne(
{ _id: userId },
{ readConcern: { level: "majority" } }
);
// This may fail during partitions to maintain consistency
Trade-offs:
- ✅ Pros: Data accuracy, ACID guarantees, simple reasoning
- ❌ Cons: Service downtime during partitions, lower availability SLA
AP Systems (Availability + Partition Tolerance)
Behavior During Partitions: Remains available but may serve stale or conflicting data. Uses eventual consistency to reconcile differences.
Implementation Patterns:
- Eventual Consistency: Asynchronous replication with convergence
- Conflict Resolution: Last-write-wins, vector clocks, CRDTs
- Gossip Protocols: Peer-to-peer state synchronization
Real-World Examples:
- Apache Cassandra: Tunable consistency with availability focus
- Amazon DynamoDB: Eventually consistent reads by default
- DNS System: Hierarchical caching with TTL-based consistency
- Social Media Feeds: Timeline inconsistencies are acceptable
Production Configuration:
-- Cassandra with AP configuration
CREATE KEYSPACE social_media
WITH REPLICATION = {
'class': 'NetworkTopologyStrategy',
'datacenter1': 3,
'datacenter2': 3
};
-- Read with eventual consistency
SELECT * FROM posts
WHERE user_id = ?
WITH CONSISTENCY LOCAL_ONE;
Trade-offs:
- ✅ Pros: High availability, geographic distribution, performance
- ❌ Cons: Data inconsistency, complex conflict resolution, eventual convergence
CA Systems (Consistency + Availability)
Behavior: Provides both consistency and availability but cannot handle network partitions.
Real-World Reality: Pure CA systems are rare in distributed environments since partitions are inevitable. Most "CA" systems are actually CP systems that appear CA in single-datacenter deployments.
Examples:
- Single-node RDBMS: PostgreSQL on one server
- Traditional monoliths: Single-datacenter applications
- In-memory databases: Redis in single-node mode
Migration Patterns:
- Start with CA for simplicity
- Evolve to CP or AP as scale requirements grow
- Use CA for components that can afford downtime
Beyond CAP: PACELC
The PACELC theorem extends CAP by considering trade-offs during normal operation:
- Partition: During partitions, choose between Availability and Consistency
- Else: During normal operation, choose between Latency and Consistency
Common Misconceptions
- "NoSQL is always AP": Many NoSQL databases offer tunable consistency
- "You must choose exactly two": Real systems often make nuanced trade-offs
- "Partitions are rare": Network issues are common in distributed systems
- "CAP applies to all operations": Different operations may have different trade-offs
Practical Implications
For System Design
- Understand your consistency requirements
- Plan for network partitions
- Consider eventual consistency models
- Design for graceful degradation
For Database Selection
- Strong consistency needed: Choose CP systems
- High availability critical: Choose AP systems
- Single datacenter: CA systems may be acceptable
Deep Dive Analysis
Performance Impact of CAP Choices
| System Type | Latency | Throughput | Availability | Use Case Fit |
|---|---|---|---|---|
| CP Systems | Higher (consensus overhead) | Lower (synchronous writes) | 99.9% (partition downtime) | Financial, Inventory |
| AP Systems | Lower (async replication) | Higher (parallel writes) | 99.99% (always available) | Social Media, Analytics |
| CA Systems | Lowest (single node) | Highest (no replication) | 99% (single point failure) | Development, Simple Apps |
Edge Cases and Failure Scenarios
Split-Brain in CP Systems:
- Network partition creates two isolated groups
- Each group believes it's the only active cluster
- Quorum mechanisms prevent dual writes
- Recovery requires manual intervention in some cases
Eventual Consistency Conflicts in AP Systems:
- Concurrent writes to same data across partitions
- Conflict resolution strategies: last-write-wins, vector clocks, CRDTs
- Business logic may need to handle inconsistent states
- Reconciliation can be complex for complex data structures
False Partition Recovery:
- Network flapping causing repeated partition/recovery cycles
- Systems may thrash between consistent and available states
- Requires careful tuning of failure detection timeouts
Interview-Focused Content
Junior Level (2-4 YOE)
Q: What is CAP theorem and why is it important?
A: CAP theorem states that in a distributed system, you can only guarantee two out of three properties: Consistency, Availability, and Partition tolerance. It's important because it helps architects understand fundamental trade-offs when designing distributed systems and choosing databases.
Q: Can you give a real-world example of each CAP combination?
A:
- CP: Banking systems that become unavailable during network issues to prevent incorrect balances
- AP: Social media feeds that may show slightly outdated posts but remain accessible
- CA: Single-database applications that work fine until the network fails
Q: What happens in a CP system during a network partition? A: A CP system will become unavailable (stop serving requests) to maintain data consistency. For example, if MongoDB's primary node gets partitioned from its replicas, it will step down and stop accepting writes until the partition heals.
Q: Why are pure CA systems rare in distributed environments? A: Because network partitions are inevitable in distributed systems. Even within a single datacenter, you can have switch failures, rack outages, or software bugs that create partitions.
Senior Level (5-8 YOE)
Q: How would you design a system that needs both high availability and strong consistency? A: This is challenging due to CAP theorem. Approaches include:
- Geographic separation of concerns: CP for critical data (payments), AP for non-critical (recommendations)
- Hybrid architectures: Synchronous replication within datacenter (CP), asynchronous cross-datacenter (AP)
- Application-level consistency: Use AP system with application logic to handle conflicts
- Consensus protocols: Raft/Paxos with careful quorum sizing
Q: Explain how Cassandra handles CAP trade-offs with tunable consistency. A: Cassandra is fundamentally AP but allows tuning consistency per operation:
QUORUMreads/writes provide strong consistency within a datacenterLOCAL_QUORUMprovides consistency within a datacenter while remaining available during cross-DC partitionsONEprovides maximum availability with eventual consistency- Applications can choose different levels for different operations
Q: How do you handle eventual consistency in application design? A: Strategies include:
- Idempotent operations: Design operations that can be safely retried
- Compensating transactions: Implement business logic to handle conflicts
- User experience design: Show "pending" states, allow users to see their own writes
- Conflict-free data types (CRDTs): Use data structures that automatically resolve conflicts
- Event sourcing: Store events rather than state, replay for consistency
Q: What are the implications of CAP theorem for microservices architecture? A: Each microservice becomes a distributed system component:
- Service boundaries: Design services to minimize cross-service consistency requirements
- Saga pattern: Handle distributed transactions across services
- Circuit breakers: Handle partition scenarios gracefully
- Event-driven architecture: Use eventual consistency between services
- Database-per-service: Each service manages its own data consistency model
Staff+ Level (8+ YOE)
Q: How does CAP theorem influence your technology selection process for a multi-billion dollar e-commerce platform? A: At this scale, different parts of the system need different CAP choices:
- User authentication: CP (Redis Cluster) - consistency critical for security
- Product catalog: AP (Cassandra) - availability more important than perfect consistency
- Payment processing: CP (traditional RDBMS with careful partitioning)
- Recommendation engine: AP (can tolerate stale data)
- Inventory: Hybrid approach with eventual consistency and business compensation logic
Q: Design a system architecture that gracefully degrades during various partition scenarios. A: Multi-layered approach:
- Application tier: Circuit breakers with fallback responses
- Data tier: Primary-secondary with automatic failover
- Cross-region: Eventually consistent replication with conflict resolution
- Business logic: Compensating workflows for consistency repair
- Monitoring: Real-time partition detection and alerting
- Graceful degradation: Core functionality remains available, advanced features may be disabled
Q: How would you implement a globally distributed system that appears strongly consistent to users? A: Approaches:
- Google Spanner approach: Global clock synchronization with atomic clocks
- Calvin approach: Deterministic transaction scheduling
- Hybrid consistency: Strong consistency for critical operations, eventual for others
- Conflict-free replicated data types (CRDTs): Data structures that converge automatically
- Application-level consensus: Business logic handles conflicts intelligently
Q: What are the implications of CAP theorem for regulatory compliance in financial systems? A: Financial systems require:
- Audit trails: Immutable transaction logs (CP requirement)
- No lost transactions: Strong consistency for all financial operations
- Regulatory reporting: Systems must handle network partitions without data loss
- Cross-border compliance: Different regions may have different availability requirements
- Disaster recovery: Regulatory requirements for RPO/RTO may influence CAP choices